环境
| 环境 | IP | 配置 | hostname | versioin | DB Port | MGR Port |
|---|---|---|---|---|---|---|
| debian11.8 | 10.10.15.11 | 2H4G | node11 | 8.0.40 | 3306 | 33066 |
| debian11.8 | 10.10.15.12 | 2H4G | node12 | 8.0.40 | 3306 | 33066 |
| debian11.8 | 10.10.15.13 | 2H4G | node13 | 8.0.40 | 3306 | 33066 |
实测低配机器 0.5核心 768M内存可运行,再低就不行了
docker的安装
略
mysql的安装
略
Tips
UUID可以使用Linux自带的
uuidgen生成
mysql master node11 配置
[mysqld]
default_authentication_plugin=mysql_native_password
# 日志文件配置
log_error=/var/log/mysql/error.log
general_log=1
general_log_file=/var/log/mysql/general.log
slow_query_log=1
slow_query_log_file=/var/log/mysql/slow.log
long_query_time=2
log_bin=/var/log/mysql/mysql-bin
# 复制和 GTID 配置
server-id=11
port=3306
report_port=3306
report_host=10.10.15.11
disabled_storage_engines=MyISAM,BLACKHOLE,FEDERATED,MEMORY
sql_require_primary_key=ON
gtid_mode=ON
enforce_gtid_consistency=ON
binlog_checksum=NONE
binlog_format=ROW
transaction_isolation=READ-COMMITTED
log_slave_updates=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
transaction_write_set_extraction=XXHASH64
#super_read_only=ON
# 组复制配置 (loose-)
plugin_load_add='group_replication.so'
loose_group_replication_start_on_boot=OFF
loose_group_replication_bootstrap_group=OFF
loose_group_replication_local_address='10.10.15.11:33066'
loose_group_replication_group_name='e2320046-8372-4519-83fa-58437f931b46'
loose_group_replication_group_seeds='10.10.15.11:33066,10.10.15.12:33066,10.10.15.13:33066'
loose_group_replication_recovery_get_public_key=ON
# group_replication_single_primary_mode=ON # 启用单主模式(可选)
# group_replication_enforce_update_everywhere_checks=OFF # 多主模式下各节点严格一致性检查,强制检查更新(可选)
# group_replication_ip_allowlist='10.10.15.0/24,10.10.15.11/32,10.10.15.12/32,10.10.15.13/32'mysql master node11 启动集群 SQL语句
# INSTALL PLUGIN group_replication SONAME 'group_replication.so';
# 查看插件,在上述启动配置中,已经默认启用了,故上面的命令不需要执行
show plugins;
# 查看UUID与server id
SELECT @@server_uuid;
SELECT @@server_id;
# 创建 REPLICATION 集群的用户 slave
SET SQL_LOG_BIN=0;
CREATE USER slave@'%' IDENTIFIED BY 'Mysql@slave';
GRANT REPLICATION SLAVE,CONNECTION_ADMIN,BACKUP_ADMIN,GROUP_REPLICATION_STREAM ON *.* TO slave@'%';
FLUSH PRIVILEGES;
SET SQL_LOG_BIN=1;
# CHANGE MASTER是老写法,也能执行成功,但是建议使用 CHANGE REPLICATION
# CHANGE MASTER TO MASTER_USER='slave', MASTER_PASSWORD='Mysql@slave' FOR CHANNEL 'group_replication_recovery';
CHANGE REPLICATION SOURCE TO SOURCE_USER='slave', SOURCE_PASSWORD='Mysql@slave' FOR CHANNEL 'group_replication_recovery';
# group_replication_bootstrap_group 仅仅是给master node11主节点使用,其他都不执行
# 只有master node11首次启用集群才需要启用,启动集群后需要关闭
SET GLOBAL group_replication_bootstrap_group=ON;
# 启动集群
START GROUP_REPLICATION;
# 只有master node11首次启用集群后,START GROUP_REPLICATION;完成必须关闭
SET GLOBAL group_replication_bootstrap_group=OFF;
# master务必谨慎使用,slave异常的时候使用
STOP GROUP_REPLICATION;
RESET MASTER;
# 查看集群信息
select * from `performance_schema`.replication_group_members;
select member_id,member_host,member_port,member_state,member_role from performance_schema.replication_group_members;
# 查看bin_log信息
SHOW VARIABLES LIKE 'relay_log%';
SHOW STATUS LIKE 'group_replication%';
show binary logs;
show binlog events;mysql master node11 SQL语句执行循序
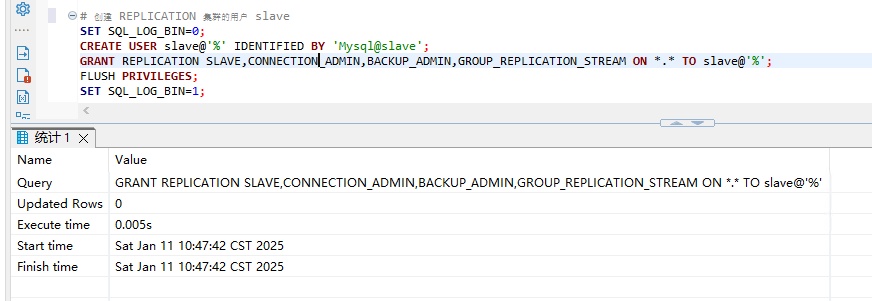
1.1 创建slave用户
SET SQL_LOG_BIN=0;
CREATE USER slave@'%' IDENTIFIED BY 'Mysql@slave';
GRANT REPLICATION SLAVE,CONNECTION_ADMIN,BACKUP_ADMIN,GROUP_REPLICATION_STREAM ON *.* TO slave@'%';
FLUSH PRIVILEGES;
SET SQL_LOG_BIN=1;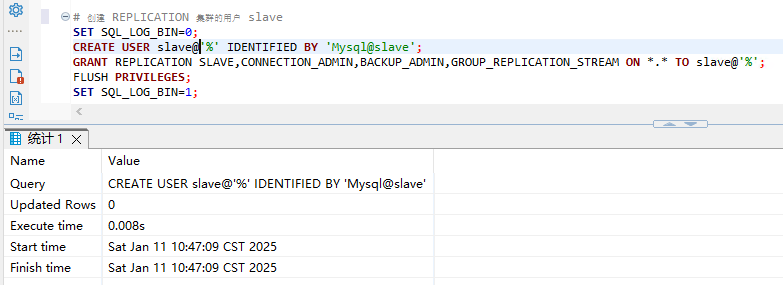
1.2 设置通道
CHANGE REPLICATION SOURCE TO SOURCE_USER='slave', SOURCE_PASSWORD='Mysql@slave' FOR CHANNEL 'group_replication_recovery';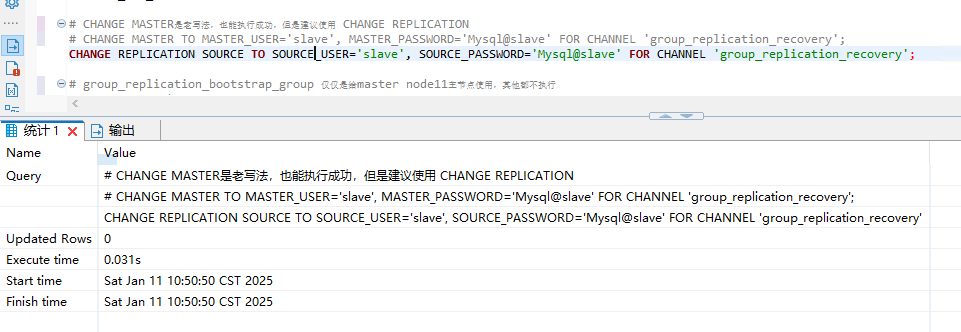
1.3 启动与停止bootstrap并且加入集群
SET GLOBAL group_replication_bootstrap_group=ON;
START GROUP_REPLICATION;
SET GLOBAL group_replication_bootstrap_group=OFF;1.4 查看集群状态
select * from `performance_schema`.replication_group_members;
mysql slave node12 配置
[mysqld]
# 低配机器降低内存使用
# innodb_buffer_pool_size = 128M
# innodb_log_buffer_size = 8M
default_authentication_plugin=mysql_native_password
# 日志文件配置
log_error=/var/log/mysql/error.log
general_log=1
general_log_file=/var/log/mysql/general.log
slow_query_log=1
slow_query_log_file=/var/log/mysql/slow.log
long_query_time=2
log_bin=/var/log/mysql/mysql-bin
# 复制和 GTID 配置
server-id=12
port=3306
report_port=3306
report_host=10.10.15.12
disabled_storage_engines=MyISAM,BLACKHOLE,FEDERATED,MEMORY
sql_require_primary_key=ON
gtid_mode=ON
enforce_gtid_consistency=ON
binlog_checksum=NONE
binlog_format=ROW
transaction_isolation=READ-COMMITTED
log_slave_updates=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
transaction_write_set_extraction=XXHASH64
#super_read_only=ON
# 组复制配置 (loose-)
plugin_load_add='group_replication.so'
loose_group_replication_start_on_boot=OFF
loose_group_replication_bootstrap_group=OFF
loose_group_replication_local_address='10.10.15.12:33066'
loose_group_replication_group_name='e2320046-8372-4519-83fa-58437f931b46'
loose_group_replication_group_seeds='10.10.15.11:33066,10.10.15.12:33066,10.10.15.13:33066'
loose_group_replication_recovery_get_public_key=ON
# group_replication_single_primary_mode=ON # 启用单主模式(可选)
# group_replication_enforce_update_everywhere_checks=OFF # 多主模式下各节点严格一致性检查,强制检查更新(可选)
# group_replication_ip_allowlist='10.10.15.0/24,10.10.15.11/32,10.10.15.12/32,10.10.15.13/32'mysql slave node12 SQL语句执行循序
2.1 创建slave用户
SET SQL_LOG_BIN=0;
CREATE USER slave@'%' IDENTIFIED BY 'Mysql@slave';
GRANT REPLICATION SLAVE,CONNECTION_ADMIN,BACKUP_ADMIN,GROUP_REPLICATION_STREAM ON *.* TO slave@'%';
FLUSH PRIVILEGES;
SET SQL_LOG_BIN=1;2.2 设置集群通道
CHANGE REPLICATION SOURCE TO SOURCE_USER='slave', SOURCE_PASSWORD='Mysql@slave' FOR CHANNEL 'group_replication_recovery';2.3 如果异常了无法加入,重置
START GROUP_REPLICATION;2.3.1 常见问题
SQL 错误 [3092] [HY000]: The server is not configured properly to be an active member of the group. Please see more details on error log.2.3.2 查看日志
2025-01-11T02:59:06.473650Z 14 [System] [MY-010597] [Repl] 'CHANGE REPLICATION SOURCE TO FOR CHANNEL 'group_replication_applier' executed'. Previous state source_host='', source_port= 3306, source_log_file='', source_log_pos= 4, source_bind=''. New state source_host='<NULL>', source_port= 0, source_log_file='', source_log_pos= 4, source_bind=''.
2025-01-11T02:59:07.563942Z 0 [ERROR] [MY-011526] [Repl] Plugin group_replication reported: 'This member has more executed transactions than those present in the group. Local transactions: 6dee4390-cf3b-11ef-8b89-72d120a396c5:1-5 > Group transactions: 6deea2e4-cf3b-11ef-8bc5-76f10517dbdf:1-5, e2320046-8372-4519-83fa-58437f931b46:1'
2025-01-11T02:59:07.563989Z 0 [ERROR] [MY-011522] [Repl] Plugin group_replication reported: 'The member contains transactions not present in the group. The member will now exit the group.'
2025-01-11T02:59:07.564028Z 0 [System] [MY-011503] [Repl] Plugin group_replication reported: 'Group membership changed to 10.10.15.12:3306, 10.10.15.11:3306 on view 17365638886605329:2.'
2025-01-11T02:59:10.622898Z 0 [System] [MY-011504] [Repl] Plugin group_replication reported: 'Group membership changed: This member has left the group.'
2025-01-11T02:59:10.624149Z 12 [System] [MY-011566] [Repl] Plugin group_replication reported: 'Setting super_read_only=OFF.'2.3.3 分析日志
由于事务不一致导致的加入失败
STOP GROUP_REPLICATION;
RESET MASTER;重置事务,并且重新加入
START GROUP_REPLICATION;返回执行成功,如遇其他问题,详情查看mysql的error.log日志
2.4 查看集群
select * from `performance_schema`.replication_group_members;
mysql slave node13 配置
[mysqld]
# 低配机器降低内存使用
# innodb_buffer_pool_size = 128M
# innodb_log_buffer_size = 8M
default_authentication_plugin=mysql_native_password
# 日志文件配置
log_error=/var/log/mysql/error.log
general_log=1
general_log_file=/var/log/mysql/general.log
slow_query_log=1
slow_query_log_file=/var/log/mysql/slow.log
long_query_time=2
log_bin=/var/log/mysql/mysql-bin
# 复制和 GTID 配置
server-id=13
port=3306
report_port=3306
report_host=10.10.15.13
disabled_storage_engines=MyISAM,BLACKHOLE,FEDERATED,MEMORY
sql_require_primary_key=ON
gtid_mode=ON
enforce_gtid_consistency=ON
binlog_checksum=NONE
binlog_format=ROW
transaction_isolation=READ-COMMITTED
log_slave_updates=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
transaction_write_set_extraction=XXHASH64
#super_read_only=ON
# 组复制配置 (loose-)
plugin_load_add='group_replication.so'
loose_group_replication_start_on_boot=OFF
loose_group_replication_bootstrap_group=OFF
loose_group_replication_local_address='10.10.15.13:33066'
loose_group_replication_group_name='e2320046-8372-4519-83fa-58437f931b46'
loose_group_replication_group_seeds='10.10.15.11:33066,10.10.15.12:33066,10.10.15.13:33066'
loose_group_replication_recovery_get_public_key=ON
# group_replication_single_primary_mode=ON # 启用单主模式(可选)
# group_replication_enforce_update_everywhere_checks=OFF # 多主模式下各节点严格一致性检查,强制检查更新(可选)
# group_replication_ip_allowlist='10.10.15.0/24,10.10.15.11/32,10.10.15.12/32,10.10.15.13/32'mysql slave node13 SQL语句执行循序
参考 node12 SQL语句执行循序
集群搭建完成

后续内容为摘录,需要自行实践
由于笔记记录时间是陆陆续续添加进来的,并未标注对应文章来源,抱歉
单主模式切换多主模式
在原来单主模式的主节点执行下面的操作
stop GROUP_REPLICATION;
set global group_replication_single_primary_mode=off;
set global group_replication_enforce_update_everywhere_checks=ON;
SET GLOBAL group_replication_bootstrap_group=ON;
START GROUP_REPLICATION;
SET GLOBAL group_replication_bootstrap_group=OFF;而对于其他的从节点,执行下面的操作
stop GROUP_REPLICATION;
set global group_replication_single_primary_mode=off;
set global group_replication_enforce_update_everywhere_checks=ON;
start group_replication;切换回单主模式(原来的主库执行)
select group_replication_switch_to_single_primary_mode();
# 指定MEMBER_ID是 a218869d-6c32-11ef-aa91-000c29298301 为主节点
select group_replication_set_as_primary("a218869d-6c32-11ef-aa91-000c29298301");添加新节点
接下来我们演示如何向MGR集群中添加一个新节点。
首先,要先完成MySQL Server初始化,创建好MGR专用账户、设置好MGR服务通道等前置工作。
接下来,直接执行命令 start group_replication 启动MGR服务即可,新增的节点会进入分布式恢复这个步骤,它会从已有节点中自动选择一个作为捐献者(donor),并自行决定是直接读取binlog进行恢复,还是利用Clone进行全量恢复。
如果是已经在线运行一段时间的MGR集群,有一定存量数据,这时候新节点加入可能会比较慢,建议手动利用Clone进行一次全量复制。还记得前面创建MGR专用账户时,给加上了 BACKUP_ADMIN 授权吗,这时候就派上用场了,Clone需要用到这个权限。
下面演示如何利用Clone进行一次全量数据恢复,假定要新增的节点是 192.168.150.24 (给它命名为 mgr4)。
在mgr4上设置捐献者
为了降低对Primary节点的影响,建议选择其他Secondary节点
mysql> set global clone_valid_donor_list=’192.168.150.24:3306′;
停掉mgr服务(如果有的话),关闭super_read_only模式,然后开始复制数据
注意这里要填写的端口是3306(MySQL正常服务端口),而不是33061这个MGR服务专用端口
stop group_replication;
set global super_read_only=0;
clone INSTANCE FROM [email protected]:3306 IDENTIFIED BY 'repl';全量复制完数据后,该节点会进行一次自动重启。重启完毕后,再次确认
group_replication_group_name、group_replication_local_address、group_replication_group_seeds 这些选项值是否正确,如果没问题
执行start group_replication 后,该节点应该就可以正常加入集群了。删除节点
在命令行模式下,一个节点想退出MGR集群,直接执行 stop group_replication 即可,如果这个节点只是临时退出集群,后面还想加回集群,则执行 start group_replication 即可自动再加入。而如果是想彻底退出集群,则停止MGR服务后,执行 reset master; reset slave all; 重置所有复制(包含MGR)相关的信息就可以了。
异常退出的节点重新加回
当节点因为网络断开、实例crash等异常情况与MGR集群断开连接后,这个节点的状态会变成 UNREACHABLE,待到超过 group_replication_member_expel_timeout + 5 秒后,集群会踢掉该节点。等到这个节点再次启动并执行 start group_replication,正常情况下,该节点应能自动重新加回集群。
重启MGR集群
正常情况下,MGR集群中的Primary节点退出时,剩下的节点会自动选出新的Primary节点。当最后一个节点也退出时,相当于整个MGR集群都关闭了。这时候任何一个节点启动MGR服务后,都不会自动成为Primary节点,需要在启动MGR服务前,先设置 group_replication_bootstrap_group=ON,使其成为引导节点,再启动MGR服务,它才会成为Primary节点,后续启动的其他节点也才能正常加入集群。可自行测试,这里不再做演示。
P.S,第一个节点启动完毕后,记得重置选项 group_replication_bootstrap_group=OFF,避免在后续的操作中导致MGR集群分裂。
节点状态监控
通过查询 performance_schema.replication_group_members 表即可知道MGR各节点的状态:
> select * from performance_schema.replication_group_members
CHANNEL_NAME |MEMBER_ID |MEMBER_HOST |MEMBER_PORT|MEMBER_STATE|MEMBER_ROLE|MEMBER_VERSION|MEMBER_COMMUNICATION_STACK|
-------------------------+------------------------------------+--------------+-----------+------------+-----------+--------------+--------------------------+
group_replication_applier|a6e68822-7a22-11ef-8a03-bc241190160e|debian12node41| 3306|ONLINE |PRIMARY |8.0.39 |XCom |
group_replication_applier|cec4cdbb-7a22-11ef-89e5-bc2411e30673|debian12node43| 3306|ONLINE |SECONDARY |8.0.39 |XCom |
group_replication_applier|cec5b0f4-7a22-11ef-89f5-bc2411fe9485|debian12node42| 3306|ONLINE |SECONDARY |8.0.39 |XCom |
输出结果中主要几个列的解读如下:
MEMBER_ID 列值就是各节点的 server_uuid,用于唯一标识每个节点,在命令行模式下,调用 udf 时传入 MEMBER_ID 以指定各节点。
MEMBER_ROLE 表示各节点的角色,如果是 PRIMARY 则表示该节点可接受读写事务,如果是 SECONDARY 则表示该节点只能接受只读事务。如果只有一个节点是 PRIMARY,其余都是 SECONDARY,则表示当前处于 单主模式;如果所有节点都是 PRIMARY,则表示当前处于 多主模式。
MEMBER_STATE
表示各节点的状态,共有几种状态:ONLINE、RECOVERING、OFFLINE、ERROR、UNREACHABLE 等,下面分别介绍几种状态。
ONLINE,表示节点处于正常状态,可提供服务。
RECOVERING,表示节点正在进行分布式恢复,等待加入集群,这时候有可能正在从donor节点利用clone复制数据,或者传输binlog中。
OFFLINE,表示该节点当前处于离线状态。提醒,在正要加入或重加入集群时,可能也会有很短瞬间的状态显示为 OFFLINE。
ERROR,表示该节点当前处于错误状态,无法成为集群的一员。当节点正在进行分布式恢复或应用事务时,也是有可能处于这个状态的。当节点处于ERROR状态时,是无法参与集群事务裁决的。节点正在加入或重加入集群时,在完成兼容性检查成为正式MGR节点前,可能也会显示为ERROR状态。
UNREACHABLE,当组通信消息收发超时时,故障检测机制会将本节点标记为怀疑状态,怀疑其可能无法和其他节点连接,例如当某个节点意外断开连接时。当在某个节点上看到其他节点处于 UNREACHABLE 状态时,有可能意味着此时部分节点发生了网络分区,也就是多个节点分裂成两个或多个子集,子集内的节点可以互通,但子集间无法互通。
当节点的状态不是 ONLINE 时,就应当立即发出告警并检查发生了什么。
在节点状态发生变化时,或者有节点加入、退出时,表 performance_schema.replication_group_members 的数据都会更新,各节点间会交换和共享这些状态信息,因此可以在任意节点查看。
MGR事务状态监控
另一个需要重点关注的是Secondary节点的事务状态,更确切的说是关注待认证事务及待应用事务队列大小。
可以执行下面的命令查看当前除了 PRIMARY 节点外,其他节点的 trx_tobe_certified 或 relaylog_tobe_applied 值是否较大:
SELECT MEMBER_ID AS id, COUNT_TRANSACTIONS_IN_QUEUE AS trx_tobe_certified, COUNT_TRANSACTIONS_REMOTE_IN_APPLIER_QUEUE AS relaylog_tobe_applied, COUNT_TRANSACTIONS_CHECKED AS trx_chkd, COUNT_TRANSACTIONS_REMOTE_APPLIED AS trx_done, COUNT_TRANSACTIONS_LOCAL_PROPOSED AS proposed FROM performance_schema.replication_group_member_stats;
id |trx_tobe_certified|relaylog_tobe_applied|trx_chkd|trx_done|proposed|
------------------------------------+------------------+---------------------+--------+--------+--------+
a6e68822-7a22-11ef-8a03-bc241190160e| 0| 0| 0| 0| 0|
cec4cdbb-7a22-11ef-89e5-bc2411e30673| 0| 0| 8| 9| 0|
cec5b0f4-7a22-11ef-89f5-bc2411fe9485| 0| 0| 8| 11| 0|其中,relaylog_tobe_applied 的值表示远程事务写到relay log后,等待回放的事务队列,trx_tobe_certified 表示等待被认证的事务队列大小,这二者任何一个值大于0,都表示当前有一定程度的延迟。
还可以通过关注上述两个数值的变化,看看两个队列是在逐步加大还是缩小,据此判断Primary节点是否"跑得太快"了,或者Secondary节点是否"跑得太慢"。
多提一下,在启用流控(flow control)时,上述两个值超过相应的阈值时(group_replication_flow_control_applier_threshold 和 group_replication_flow_control_certifier_threshold 默认阈值都是 25000),就会触发流控机制
其他监控
另外,也可以查看接收到的事务和已执行完的事务之间的差距来判断:
> SELECT RECEIVED_TRANSACTION_SET FROM performance_schema.replication_connection_status WHERE channel_name = 'group_replication_applier' UNION ALL SELECT variable_value FROM performance_schema.global_variables WHERE variable_name = 'gtid_executed'
RECEIVED_TRANSACTION_SET |
-----------------------------------------------------------------------------------+
554b3409-7cef-4c06-9c90-8a073db14ba4:1-24,¶a6e68822-7a22-11ef-8a03-bc241190160e:1-5|
554b3409-7cef-4c06-9c90-8a073db14ba4:1-24,¶a6e68822-7a22-11ef-8a03-bc241190160e:1-5|mysqlshell/mysqlroute
mysql-shell 创建集群
wget https://downloads.mysql.com/archives/get/p/43/file/mysql-shell-8.0.37-linux-glibc2.28-x86-64bit.tar.gz
tar -zxvf mysql-shell-8.0.37-linux-glibc2.28-x86-64bit.tar.gz
./mysql-shell-8.0.37-linux-glibc2.28-x86-64bit/bin/mysqlsh
shell.connect('root@mysql-01:3306');
var cluster = dba.createCluster('cluster');
# mgr集群默认创建
cluster.addInstance('mysql-02:3306');
cluster.addInstance('mysql-03:3306');
cluster.status();keepalived 保活 mysqlroute
mysql-01
global_defs {
router_id master
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 1
priority 100 # 最高优先级
advert_int 1
virtual_ipaddress {
172.20.0.20
}
}mysql-02
global_defs {
router_id backup1
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 1
priority 90 # 次高优先级
advert_int 1
virtual_ipaddress {
172.20.0.20
}
}mysql-03
global_defs {
router_id backup2
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 1
priority 80 # 最低优先级
advert_int 1
virtual_ipaddress {
172.20.0.20
}
}